Amino acids are organic molecules containing two functional groups, an amino group (NH2) and a carboxy group (-COOH), as well as a side chain, called an R group. α-amino acids, as shown above, have both functional groups on the α-carbon. These include all 20 proteinogenic amino acids, which are the ones encoded for by the human genetic code, and the focus of MCAT biochemistry. From the central dogma of biology, amino acids are coded for by DNA, and polypeptide chains of amino acids make up proteins.
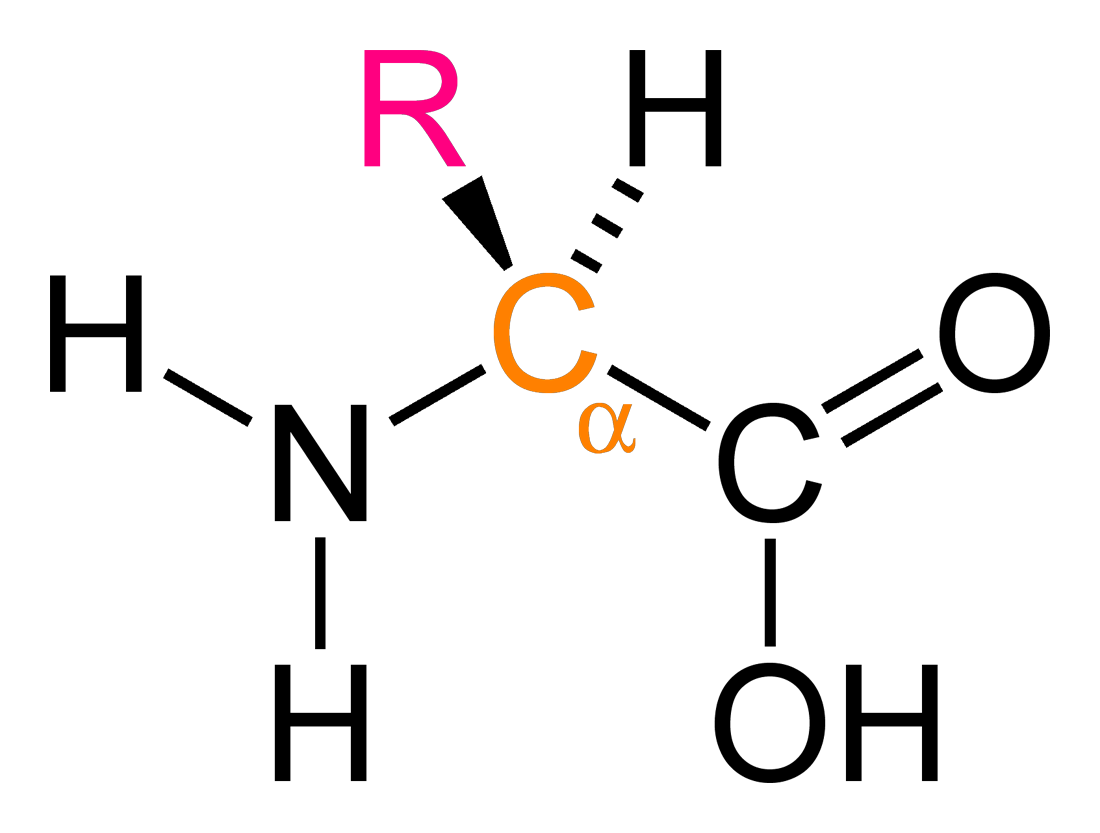
The R group determines the chemical properties of the amino acid. The 20 proteinogenic amino acids we’ll focus on all have different R-groups (amino acids from now on will refer exlusively to these). From a stereochemistry perspective, all amino acids are chiral except for glycine, who’s R-group is just -H. All chiral amino acids used in eukaryotes are L-amino acids. All except cysteine have an (S) absolute configuration
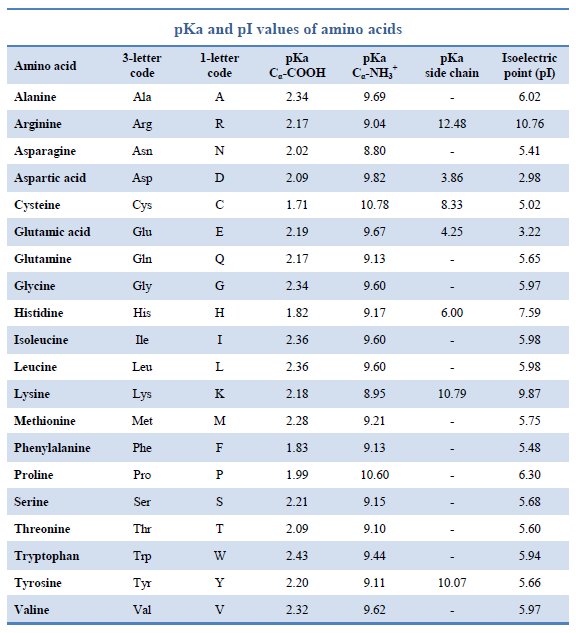
The structure of amino acids and their abbreviations should definitely be memorized. You should also memorize relevant side chain pKa values. Let’s begin with charged amino acids. These are aspartate, glutamate, arginine, lysine, and histidine. The first two are negatively charged (acidic), and the remaining three are positively charged (basic). Histadine has the unique ability to gain a proton, making it useful in the catalytic triad of chymotrypsin. The armotic amino acids, which have an aromatic ring in their structure, are tryptophan, phenylalanine, and tyrosine. Five amino acids have polar side chains: serine and threonin with -OH groups, asparagine and glutamine with amides, and cysteine with a thiol (-SH). What makes these side chains polar? They have the ability to form hydrogen bonds, especially with water.

Hydrophobic amino acids tend to reside in the interiors of proteins, away from the surface and water. Hydrophillic amino acids tend to reside on the surface of the protein. Hydrophobic amino acids are those with long alkyl side chains-alanine, isoleucine, leucine, valine, and phenylalanine. Hydrophillic amino acids include all the charged side chains -histidine, arginine, lysine, glutamate, and aspartate, as well as amides asparagine and glutamine.
Acid-Base chemistry of Amino Acids is very important to know, since all amino acids have both an acidic carboxylic acid group and a basic amino group. This makes amino acids an amphhoteric species, meaning that they can either accept or donate a proton, depending on the pH of their environment. At low pH, ionizable groups tend to be protonated. At high pH, ionizable groups tend to be deprotonated. Recall pKa relationship with pH: the pKa of a group is the pH at which half the molecules are deprotonated, or [HA] = [A-] (HA = protonated version, A- = deprotonated version). If the pH is less than the pKa, a majority of the species will be protonated. If the pH is greater than the pKa, a majority of the species will be deprotonated. As you can see from the chart above, all amino acids have at least 2 pKa values, one for the carboxylic acid and one for the amino group, though those with ionizable side chains have 3 pKa values.
Remember that ph = -log[H+] = pKa + log([A-]/[HA]). This is the Henderson-Hasselbach equation.
As an example, let us look at glycine, the simplest amino acid with side chain (-H), under three different conditions: acidic (pH =1), intermediate (pH = 7), and basic (pH =11). Glycine has a carboxylic acid group pKa of 2.34 and an amino group pKa of 9.6. Under acidic conditions, when the pH is below both pKa’s, the amino group of normally NH2 will be fully protonated to NH3+ and be positively charged, while the carboxylate group of normally -COOH is also fully protonated to the same -COOH and thus neutral. So glycine has a charge of +1 at pH = 1. Indeed, amino acids tend to be positively charged at acidic pH values. Under intermediate conditions of pH = 7.4, the normal pH of human blood, we have moved above the pKa of the carboxylate and thus it will be deprotonated into -COO−, its conjugate base form. However, we’re still below the pKa of the amino group, so the amino group is still fully protonated at NH3+, with a positive charge. Since there’s one positive charge and one negative charge, the charges cancel and amino acid is electrically neutral. These are called zwitterions. Under basic conditions of pH = 11, we are above the pKa of the carboxylate group, which is deprotonated to -COO− and has a negative charge. We are also above the pKa of the amino group, which is deprotonated to -NH2, with no charge. So glycine has an overall negative charge at basic pH’s. For amino acids with an ionizable side chain, just treat it similiarly with it’s side chain pKa value. The videos below is a good example of this overall process.
The isoelectric point (pI) is the pH at which every molecule is electrically neutral. For neutral amino acids, the pI can be calculated by averaging the pKa values for the amino and carboxyl groups. For glycine, this would be (2.34 + 9.60) / 2 = 5.97. For oligopeptides or amino acids with charged side chains, the pI is calculated by averaging the pKa’s that bound the pH at which the peptide or amino acid has a charge of 0. In general, amino acids with acidic side chains have pI values well below 6, neutral amino acids are right around 6, and amino acids with basic side chains have pI values well above 6.
Peptides are chains of amino acids, which are sometimes called residues. Dipeptides consist of 2 amino acid resiudes; tripeptides of three, and so forth. The term oligopeptide is used for relatively small peptides, usually of about 20, whereas longer chains are called polypeptides. Proteins are made from poplypeptide chains. Peptide bond formation occurs between the carboxylic acid of one amino acid and the amino group of another, forming a type of amide bond. Water is released in the reaction, so it makes sense it is called a dehydration reaction. It can also be called a condensation reaction and mechanistically is an acyl substitution reaction. Since the peptide bond has a resonance structure, the C-N bond has partial double bond character and therefore is rigid and doesn’t rotate. Rotation about the other bonds however isn’t restricted. When a peptide bond is formed, the free amino end is known as the N-terminus and the free carboxyl end is known as the C-terminus. By convention, peptides are drawn with the N-terminus on the left and the C-terminus on the right. Peptides are also synthesized in the same direction, from N-terminus to C-terminus. ΔG > 0 for bond-formation reactinons, meaning they are thermodynamically unfavorable. Of course, this means ΔG < 0 for peptide bond hydrolysis, when the peptide bonds break apart. So how to peptide bonds form? Ribosomes couple the unfavorable condensation reaction with ATP hydrolysis, a common theme in biochemistry for driving unfavorable reactions. So why don’t peptide bonds break apart? They do, except it’s really slow without enzymes called proteases. In organic chemistry, amides can be hydrolyzed using acid or base catalysis. Proteases only cleave at specific points in the peptide chain. Water is consumed in peptide bond hydrolysis. The exact mechanism is described in the enzymes section.
There are two main methods of determining the amino acid sequence of a peptide. For a relatively short peptide, normally ~50 residues, Edman degredation removies one residue at a time from the N-terminus. For longer peptides, mass spectrometry can be used. First, long peptides are digested into smaller sections by specific proteases. Trypsin cleaves after R/K (positively charged), chymotrypsin after F/W/Y (aromatic), and V8 after D/E (negatively charged). Then the fragments are ionized by electro-spray ionization (ESI) and sequenced using tandem mass spectrometry. The resulting m/z spectra can be used to determine the composition of fragments. For more on mass spectroscopy: https://www2.chemistry.msu.edu/faculty/reusch/VirtTxtJml/Spectrpy/MassSpec/masspec1.htm
Alternatively, we can translate direct coding regions in the genome to decipher peptide amino acid sequences.
So how can just 20 amino acids give rise to hundreds of thousands of unique proteins? Through primary, secondary, tertiary, and quaternary protein structure, of course. Primary protein structure is simply the sequence of amino acids that make up the peptide. Primary structure is caused by the peptide bonds discussed earlier. Secondary structure is local structure of neighboring amino acids and are the result of hydrogen bonding between nearby amino acids. Recall that peptides can rotate at bonds other than the amide bond between residues. In the α-helix, the number of hydrogen bonds is maximized by having every main chain carbonyl oxygen hydrogen bond to an amide proton 4 residues ahead.

The α-helix is an important component of keratin, which is just a long dimer of α-helices. Keratin is a fibrous structural protein foud in skin, hair, fingernails, and wool. Despite appearances, α-helices are not hollow. β-pleated sheets are formed when peptide chains lie alongside one another, forming hydrogen bonds between the chains. β-sheets can be parallel or anti-parallel, as shown below. This just refers to the directions of the chains relative to each other. Remember that chains start from the N-terminus and end at the C-terminus.


Beta sheets can be made of a combination of parllel and antiparallel chains. Recall that proline has a bizarre rigid cyclic structure. Its presence in polypetites introdues a kink, and thus is rarely found in both alpha helices or beta sheets, except in helices that cross the cell membrane. However, proline is often found at the start of alpha helices and in the turns between the chains of a beta sheet. Both α-helices and β-sheets maximize H-bonding by main chain NH and CO. Both α-helices and β-sheets place the amino acid side chains (R groups) on the outside. H-bonding is local in α-helices but not in β-sheets.
Proteins can be fibrous or globular. As the names suggest, fibrous proteins have structures that resemble sheets or long strangs, while globular proteins ten to be spherical. These structures are due to tertiary and quaternary protein structure. A protein’s tertiary structure is its three-dimensional shape and is the result of moving hydrophobic aminoa cid side chains into the interior the protein. Hydrogen bonds also play a part in the tertiary structure. Disulfide bonds in tertiary structures are formed when two cysteine molecules become oxidized to form cystine, allowing an S-S bond. These bonds create loops in the protein chain, and can determine how wavy or curly human hair is: the more disulfide bonds, the curlier it is. If a protein looses its tertiary structure, it looses its function. This process is known as denaturation.
It is important to understand the energetics on protiein folding. Enthalpy, ΔH < 0, favors folding, due largely to the increased van der Waals contacts. H-bonds and electrostatic interactions also contribute. Entropy, TΔS < 0, favors unfolding. The conformational entropy of a protein is greater when unfolded (decreasing order). The entropy of water is also greater when a protein is folded. Entropy can aslo explain why hydrophobic residues tend to accumulate in the center of proteins and hydrophilic residues tend to accumulate on the surface. Remember that whenever a solute dissolves in a solvent, the nearby solvent molecules form a solvation layer around the solute. When a hydrophobic side chain is plalced in aqueous solution, the water molecules in the solvation layer cannot form hydrogen bonds with the side chain, forcing the water molecules into specific arrangements to maximize hydrogen bonding. This results in a negative change in entropy. On the other hand, hydrophilic residues on the exterior of the protein allows the nearby water molecules more latitude in their positioning, thus increasing their entropy.
Not all proteins have quaternary structure, though all proteins have primary, secondary, and tertiary structure. Quaternary structure exists only for proteins with more than one polypeptide chain, and simply put is the interaction between the different polypeptide chains, which are normally globular. These subunits come together to induce cooperativity, or allosteric effects, allowing one subunit to undergo conformational or structural changes to enhance of reduce the activity of other subunits. Hemoglobin is a classic example of quatrnary structure, with four subunits that can each bind one molecule of oxygen.
Conjugated proteins are proteins that have a prosthetic group attached. These prosthetic groups can be organic molecules, such as vitamins, metal ions, or lipids, carbohydrates, and nucleic acids. These are intuitively referred to as lipoproteins, glycoproteins, and nucleoproteins, respectively. Prosthetic groups play a large role in determining the function of their respective proteins. The iron in heme groups, which make up hemoglobin, is necessary to bind oxygen.